Solving Math Problems with Precision: Python Code Execution with E2B and Hal9
Overview
In the world of large language models (LLMs), generating accurate and precise answers to math problems can be challenging due to hallucinations and inherent limitations in numerical reasoning. By integrating Python code execution into the LLM workflow, we can greatly enhance precision and reliability. This guide demonstrates how to combine the power of E2B’s sandboxed Python execution with Hal9 to create a robust Math Problems Resolver.
Build a Math Resolver step by step
1. Environment Setup and Initialization
The first step involves setting up the required environment by importing necessary libraries, loading environment variables, and initializing API clients. This ensures that both Hal9 and E2B are ready to work together.
from e2b_code_interpreter import Sandbox
from dotenv import load_dotenv
from openai import OpenAI
import os
import json
import hal9 as h9
load_dotenv()
E2B_API_KEY = "YOUR E2B API KEY"
if E2B_API_KEY == "":
print("You need to register in e2b -> https://e2b.dev/ and get your API key to use this chat")
else:
# Initialize OpenAI client with Hal9 proxy
openai_client = OpenAI(
base_url="https://api.hal9.com/proxy/server=https://api.openai.com/v1/",
api_key=os.getenv("HAL9_TOKEN")
)
2. Defining the Python Code Execution Tool
To enable LLMs to execute Python code, we define a tool that describes the functionality required to run code snippets. This tool bridges the gap between the LLM’s language understanding and actual Python code execution for solving math problems.
# Define tool for executing Python code
tools = [{
"type": "function",
"function": {
"name": "execute_python",
"description": "Execute Python code in a Jupyter notebook cell for solving math problems.",
"parameters": {
"type": "object",
"properties": {
"code": {
"type": "string",
"description": "Python code to compute the math problem."
}
},
"required": ["code"]
}
}
}]
3. Message Management
The code below demonstrates how to manage the conversation by loading previous messages, setting up an initial system prompt, and appending new user inputs.
# Load previous messages or initialize an empty list
messages = h9.load("messages", [])
# Add initial system message if messages list is empty
if len(messages) < 1:
messages.append({
"role": "system",
"content": "Math Problems Resolver: Ready to solve your math challenges using Python code execution."
})
# Append user input to messages
user_input = h9.input()
messages.append({"role": "user", "content": user_input})
4. Integrating Python Code Execution via E2B Sandbox
To reduce hallucinations and increase precision in mathematical computations, the LLM can call the execute_python tool. When invoked, the code is executed in a secure E2B sandbox environment, ensuring accurate results and safe code execution.
# Get response from OpenAI with tool usage enabled
response = openai_client.chat.completions.create(
model="o3-mini",
messages=messages,
tools=tools,
tool_choice="required"
)
# Process response and execute tool calls if any
response_message = response.choices[0].message
if response_message.tool_calls:
for tool_call in response_message.tool_calls:
messages.append({
"role": "assistant",
"tool_calls": [{
"id": tool_call.id,
"type": "function",
"function": {
"arguments": tool_call.function.arguments,
"name": tool_call.function.name,
},
}]
})
if tool_call.function.name == "execute_python":
# Execute Python code in a sandbox environment
with Sandbox(api_key=E2B_API_KEY) as sandbox:
code = json.loads(tool_call.function.arguments)['code']
print(f"Python code executed: \n\n ```{code}```\n")
execution = sandbox.run_code(code)
result = execution.text
# Append the execution result to messages
messages.append({
"role": "tool",
"name": "execute_python",
"content": result,
"tool_call_id": tool_call.id,
})
else:
messages.append({
"role": response_message.role,
"content": response_message.content
})
5. Finalizing the Response
After processing tool calls and executing the Python code, the conversation history is updated and saved. The final response is then generated, ensuring that users receive precise and context-aware solutions to their math problem
# Save messages and get the final response
final_response = openai_client.chat.completions.create(
model="o3-mini",
messages=messages
)
final_response_message = final_response.choices[0].message
messages.append({
"role": final_response_message.role,
"content": final_response_message.content
})
print(final_response_message.content)
h9.save("messages", messages)
The Power of Python Execution in Math Problem Solving
By integrating Python code execution into the LLM workflow:
- Precision is Enhanced: Executing actual code reduces the risk of hallucinated results, especially in complex math computations.
- Reliability is Boosted: The E2B sandbox provides a safe and controlled environment to run code, ensuring that the results are accurate.
Experience the power of integrating Python code execution with LLMs. Whether you're tackling complex equations or simply exploring math problem solving, this setup is designed to deliver reliable results. Try it here.
Complete code on GitHub: Hal9 e2b Repository.
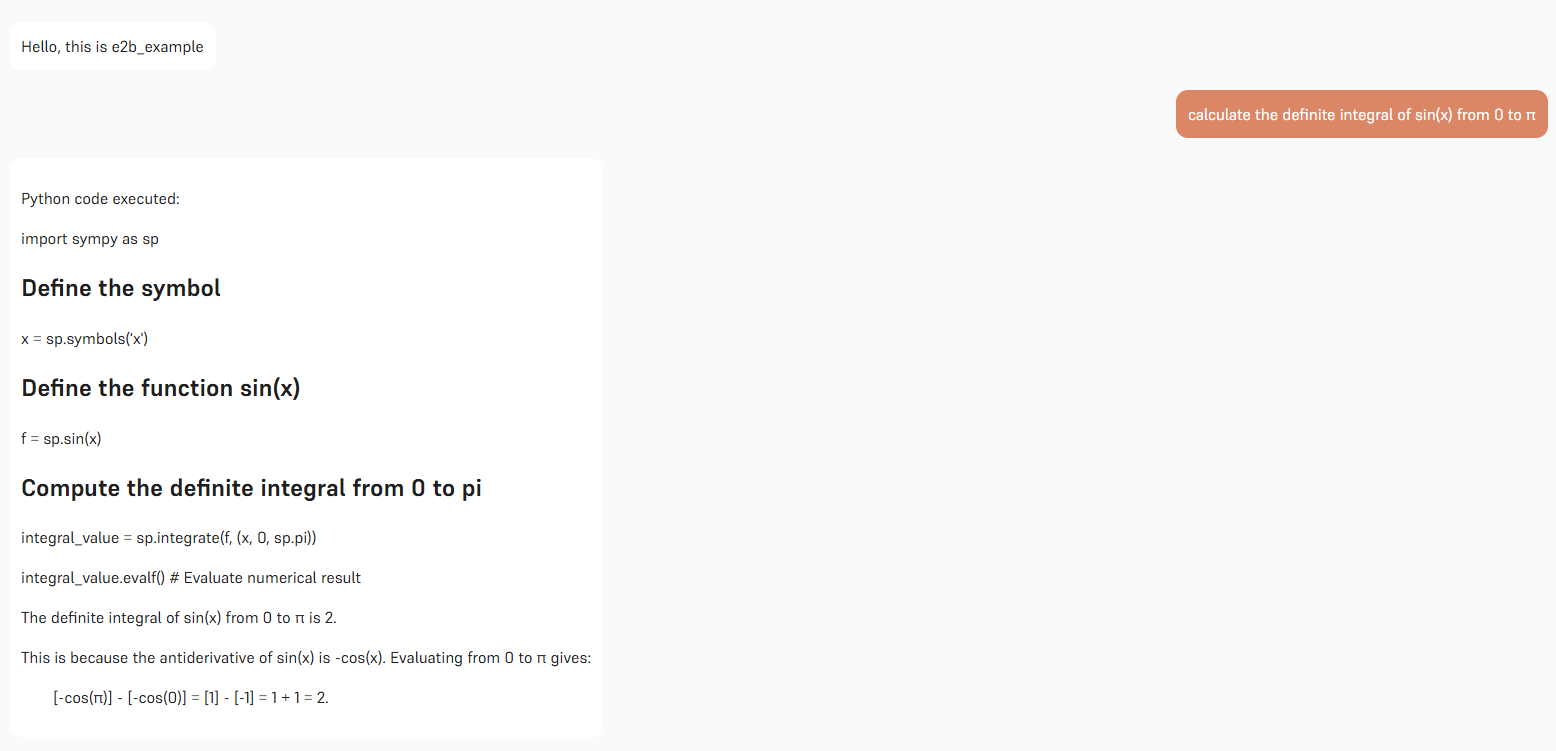
Conclusion
The fusion of E2B��s secure Python code execution and Hal9’s interactive chat interface provides a groundbreaking approach to reducing hallucinations in math problem solving. By executing code on-demand, this system bridges the gap between language models’ conversational abilities and the precision of programmatic computation.